Tutorials
Meer doen met PostgreSQL [1]
Meer mogelijk maken door gebruik te maken van een aantal mogelijkheden die PostgreSQL te bieden heeft.
Pagina 1
Inleiding
Naast de veelgebruikte statements INSERT, SELECT, UPDATE en DELETE kun je véél meer met een database-systeem. In dit artikel ga ik dieper in op de mogelijkheden welke PostgreSQL biedt. Dit RDBMS (Relationeel Database Management Systeem) is een volwassen opensource database-systeem welke zich kan meten met bijvoorbeeld dure varianten zoals Oracle en Microsoft SQL Server. Meer informatie vindt je op www.postgresql.org. Er is ook gewoon een Windows-versie beschikbaar dus je kunt er ook thuis mee spelen!
Achtereenvolgens zal ik de volgende onderwerpen behandelen:
- Beschrijving van een case
- Overerving in PostgreSQL: particuliere klant en zakelijke klant
- Aanmaken van tabellen en het leggen van relaties
- Views
- PL/pgSQL functies
- Triggers
- Check constraints en domains
Voor het schrijven van de functies in PostgreSQL zal ik gebruik maken van PL/pgSQL, deze “Procedural Language” wordt meegeleverd met het systeem en zal misschien alleen nog geactiveerd hoeven te worden, je kunt dit in de pgsql-shell doen met het volgende commando:
createlang plpgsql database_name_hier
Voor het beheer van je PostgreSQL-database kun je gebruik maken van pgAdmin, deze vindt je op www.pgadmin.org en wordt bij een Windows-installatie ook meegeleverd.
Let op, het is een vrij lange tutorial geworden, ik hoop van harte dat je er iets mee kunt, stel je vragen s.v.p. bij de reacties dan kan ik er snel op reageren. Het is onmogelijk om alles tot in detail uit te leggen of toepasbaar te maken voor iedereen, met een stuk inzicht en zelfvertrouwen kom je echter heel ver.
Veel leesplezier!
Achtereenvolgens zal ik de volgende onderwerpen behandelen:
- Beschrijving van een case
- Overerving in PostgreSQL: particuliere klant en zakelijke klant
- Aanmaken van tabellen en het leggen van relaties
- Views
- PL/pgSQL functies
- Triggers
- Check constraints en domains
Voor het schrijven van de functies in PostgreSQL zal ik gebruik maken van PL/pgSQL, deze “Procedural Language” wordt meegeleverd met het systeem en zal misschien alleen nog geactiveerd hoeven te worden, je kunt dit in de pgsql-shell doen met het volgende commando:
createlang plpgsql database_name_hier
Voor het beheer van je PostgreSQL-database kun je gebruik maken van pgAdmin, deze vindt je op www.pgadmin.org en wordt bij een Windows-installatie ook meegeleverd.
Let op, het is een vrij lange tutorial geworden, ik hoop van harte dat je er iets mee kunt, stel je vragen s.v.p. bij de reacties dan kan ik er snel op reageren. Het is onmogelijk om alles tot in detail uit te leggen of toepasbaar te maken voor iedereen, met een stuk inzicht en zelfvertrouwen kom je echter heel ver.
Veel leesplezier!
Pagina 2
Voorbeeld-case
Om een beetje feeling te krijgen met een “real-life-situatie” heb ik een scenario opgesteld waarbij ik alle genoemde zaken aan bod laat komen. Het voorbeeld zal zich slechts beperken tot SQL, de PHP-cliënt is niet bijzonder moeilijk. Het voorbeeld is misschien wat abstract maar geeft hopelijk wel een goed beeld van een toepassing.
Ontwikkel een database waarin medewerkers van een hotelketen kunnen worden opgeslagen, de volgende entiteiten zijn aanwezig:
- Hotels
- Medewerkers
- Klanten (particulier)
- Klanten (zakelijk)
- Reserveringen
Een en ander is gevisualiseerd in onderstaand klassendiagram, hierin staan de relaties weergegeven:
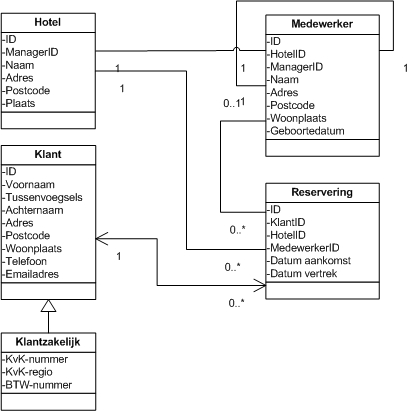
Toelichting:
- Een hotel heeft 1 manager.
- Een medewerker heeft 0 of 1 manager, als er geen manager aan een medewerker is toegekend zal dit de hoogste pief zijn :)
- Een medewerker is werkzaam bij 1 hotel
- Een klant heeft 0 of meer reserveringen
- Een medewerker behandeld 0 of meer reserveringen
Ontwikkel een database waarin medewerkers van een hotelketen kunnen worden opgeslagen, de volgende entiteiten zijn aanwezig:
- Hotels
- Medewerkers
- Klanten (particulier)
- Klanten (zakelijk)
- Reserveringen
Een en ander is gevisualiseerd in onderstaand klassendiagram, hierin staan de relaties weergegeven:
Toelichting:
- Een hotel heeft 1 manager.
- Een medewerker heeft 0 of 1 manager, als er geen manager aan een medewerker is toegekend zal dit de hoogste pief zijn :)
- Een medewerker is werkzaam bij 1 hotel
- Een klant heeft 0 of meer reserveringen
- Een medewerker behandeld 0 of meer reserveringen
Pagina 3
Overerving in PostgreSQL
PostgreSQL is een databasesysteem dat enkele object georiënteerde zaken in zich heeft, een van deze technieken is overerving. Het is mogelijk om tabellen aan te maken die eigenschappen (dus kolommen) overerven van een andere tabel. In het voorbeeld is dit ideaal toe te passen, we hebben gezien dat er 2 type klanten zijn, namelijk particulier en zakelijk. Hier komt dus een stukje specialisatie / generalisatie om de hoek kijken: Klant is de superklasse, Klantzakelijk is een specialisatie op de superklasse Klant.
In PostgreSQL dienen we dus een hoofdtabel ‘klant’ aan te maken welke alle gedeelde velden bevat, deze velden zijn voor ieder type klant aanwezig:
- ID
- Voornaam
- Tussenvoegsels
- Achternaam
- Adres
- Postcode
- Woonplaats
- Telefoonnummer
- Emailadres
Voor een zakelijke klant zouden er nog extra velden kunnen zijn welke voor een particuliere klant helemaal niet van toepassing zijn, zoals:
- KvK-nummer
- KvK-regio
- BTW-nummer
In SQL-code ziet dit er als volgt uit:
Door gebruik te maken van het statement INHERITS (klant) zal de tabel “klantzakelijk” alle beschikbare velden van de tabel “klant” overerven.
In PostgreSQL dienen we dus een hoofdtabel ‘klant’ aan te maken welke alle gedeelde velden bevat, deze velden zijn voor ieder type klant aanwezig:
- ID
- Voornaam
- Tussenvoegsels
- Achternaam
- Adres
- Postcode
- Woonplaats
- Telefoonnummer
- Emailadres
Voor een zakelijke klant zouden er nog extra velden kunnen zijn welke voor een particuliere klant helemaal niet van toepassing zijn, zoals:
- KvK-nummer
- KvK-regio
- BTW-nummer
In SQL-code ziet dit er als volgt uit:
CREATE TABLE klant
(
klant_id serial NOT NULL,
voornaam varchar(100) NOT NULL,
tussenvoegsels varchar(50),
achternaam varchar(100) NOT NULL,
adres varchar(100) NOT NULL,
postcode varchar(7) NOT NULL,
woonplaats varchar(100) NOT NULL,
telefoonnummer varchar(15),
emailadres varchar(100),
CONSTRAINT klant_pkey PRIMARY KEY (klant_id)
)
WITH OIDS;
CREATE TABLE klantzakelijk
(
kvk_nummer varchar(50),
kvk_regio varchar(50),
btw_nummer varchar(50)
) INHERITS (klant)
WITH OIDS;
Door gebruik te maken van het statement INHERITS (klant) zal de tabel “klantzakelijk” alle beschikbare velden van de tabel “klant” overerven.
Pagina 4
Aanmaken van tabellen en het leggen van relaties
De tabellen “klant” en “klantzakelijk” zijn inmiddels aangemaakt, nu dienen de hotels, medewerkers en reserveringen nog te worden aangemaakt. Bij het aanmaken van de tabellen zal ik regelmatig verwijzen naar het klassendiagram, de functie hiervan zal je dan (hopelijk) duidelijk worden.
Bij het aanmaken van de tabel “medewerker” is er een relatie gelegd op de kolom “manager_id” naar het veld “medewerker_id” in dezelfde tabel. Een medewerker kon volgens het klassendiagram een manager hebben. Met deze relatie wordt afgedwongen dat het manager_id moet voorkomen als medewerker_id in medewerker, het verwijderen van een medewerker kan niet zolang hij nog manager is van andere medewerkers.
Een hotel heeft altijd één manager, daarom is het veld aangemaakt met de eigenschap NOT NULL, het veld mag niet leeg zijn. Er is een relatie gelegd op de kolom manager_id welke verwijst naar medewerker_id in de tabel medewerker, ook hier wordt op database-niveau afgedwongen dat de manager moet bestaan en nooit kan worden verwijderd zolang er nog hotels zijn welke hij ‘managed’.
Een reservering bevat ALTIJD de volgende gegevens: hotel_id, klant_id en medewerker_id, daarom zijn ook deze velden NOT NULL en verwijzen ze met relaties naar de betreffende tabellen. In deze opzet is het zo gemaakt dat als een klant wordt weggegooid ook meteen zijn reserveringen worden verwijderd (ON DELETE CASCADE), idem bij het verwijderen van een hotel en medewerker. Of dit wenselijk is is afhankelijk van het systeem dat je bouwt.
CREATE TABLE medewerker
(
medewerker_id serial NOT NULL,
hotel_id int8,
manager_id int8,
naam varchar(150) NOT NULL,
adres varchar(100) NOT NULL,
postcode varchar(7) NOT NULL,
woonplaats varchar(100) NOT NULL,
CONSTRAINT pk_medewerker PRIMARY KEY (medewerker_id),
CONSTRAINT fk_manager FOREIGN KEY (manager_id) REFERENCES medewerker (medewerker_id) ON UPDATE RESTRICT ON DELETE RESTRICT
)
WITH OIDS;
Bij het aanmaken van de tabel “medewerker” is er een relatie gelegd op de kolom “manager_id” naar het veld “medewerker_id” in dezelfde tabel. Een medewerker kon volgens het klassendiagram een manager hebben. Met deze relatie wordt afgedwongen dat het manager_id moet voorkomen als medewerker_id in medewerker, het verwijderen van een medewerker kan niet zolang hij nog manager is van andere medewerkers.
CREATE TABLE hotel
(
hotel_id serial NOT NULL,
manager_id int8 NOT NULL,
naam varchar(100) NOT NULL,
adres varchar(150) NOT NULL,
postcode varchar(7) NOT NULL,
plaats varchar(100) NOT NULL,
CONSTRAINT pk_hotel PRIMARY KEY (hotel_id),
CONSTRAINT fk_manager FOREIGN KEY (manager_id) REFERENCES medewerker (medewerker_id) ON UPDATE RESTRICT ON DELETE RESTRICT
)
WITH OIDS;
Een hotel heeft altijd één manager, daarom is het veld aangemaakt met de eigenschap NOT NULL, het veld mag niet leeg zijn. Er is een relatie gelegd op de kolom manager_id welke verwijst naar medewerker_id in de tabel medewerker, ook hier wordt op database-niveau afgedwongen dat de manager moet bestaan en nooit kan worden verwijderd zolang er nog hotels zijn welke hij ‘managed’.
CREATE TABLE reservering
(
reservering_id serial NOT NULL,
hotel_id int8 NOT NULL,
klant_id int8 NOT NULL,
medewerker_id int8 NOT NULL,
datum_aankomst date,
datum_vertrek date,
CONSTRAINT pk_reservering PRIMARY KEY (reservering_id),
CONSTRAINT fk_hotel FOREIGN KEY (hotel_id) REFERENCES hotel (hotel_id) ON UPDATE CASCADE ON DELETE CASCADE,
CONSTRAINT fk_klant FOREIGN KEY (klant_id) REFERENCES klant (klant_id) ON UPDATE CASCADE ON DELETE CASCADE,
CONSTRAINT fk_medewerker FOREIGN KEY (medewerker_id) REFERENCES medewerker (medewerker_id) ON UPDATE CASCADE ON DELETE CASCADE
)
WITH OIDS;
Een reservering bevat ALTIJD de volgende gegevens: hotel_id, klant_id en medewerker_id, daarom zijn ook deze velden NOT NULL en verwijzen ze met relaties naar de betreffende tabellen. In deze opzet is het zo gemaakt dat als een klant wordt weggegooid ook meteen zijn reserveringen worden verwijderd (ON DELETE CASCADE), idem bij het verwijderen van een hotel en medewerker. Of dit wenselijk is is afhankelijk van het systeem dat je bouwt.
Pagina 5
Views
Een view in een database is een soort venster dat je over je bestaande datastructuur kan leggen. Dit venster kun je bijvoorbeeld gebruiken in een SELECT-statement, stel dat je deze query hebt welke alle namen van de hotels toont met de naam van de manager en het totaal aantal reserveringen van dat hotel:
Dat is nogal een lap tekst om uit te voeren. We zouden nu een view kunnen maken welke de uitvoer van deze query bevat:
Er is nu een view aangemaakt welke je kunt aanroepen. In plaats van die lange query uit te voeren kun je nu zeggen:
De view wordt bewaard op de database en hoef je dus maar 1 keer aan te maken. Een voordeel van een view is dat je de onderliggende datastructuur kunt “verbergen”. Als je applicatie zijn data uit de views haalt maakt het in feite niet uit hoe je tabellen en kolommen heten, zolang de uitvoer van je view maar consistent is met je applicatie. Daarnaast kunnen rechten worden uitgedeeld op een view, zo zou je een gebruiker geen rechten hoeven te geven op al je tabellen maar alleen op de views, security dus!
Een view is read-only, je kunt er dus geen updates of inserts op uitvoeren, dit kan in sommige situaties echter wél door middel van rules, deze behandel ik niet aangezien ik persoonlijk het nut er niet helemaal van zie :)
Zie http://www.postgresql.org/docs/8.1/interactive/rules-views.html voor meer informatie hierover.
SELECT h.naam, m.naam AS manager, COUNT(r.*) AS aantal
FROM hotel AS h
INNER JOIN medewerker AS m ON h.manager_id=m.medewerker_id
INNER JOIN reservering AS r ON r.hotel_id=h.hotel_id
GROUP BY r.hotel_id, h.naam, m.naam
Dat is nogal een lap tekst om uit te voeren. We zouden nu een view kunnen maken welke de uitvoer van deze query bevat:
CREATE OR REPLACE VIEW view_aantal_reserveringen AS
SELECT h.naam, m.naam AS manager, count(r.*) AS aantal
FROM hotel h
JOIN medewerker m ON h.manager_id = m.medewerker_id
JOIN reservering r ON r.hotel_id = h.hotel_id
GROUP BY r.hotel_id, h.naam, m.naam;
Er is nu een view aangemaakt welke je kunt aanroepen. In plaats van die lange query uit te voeren kun je nu zeggen:
SELECT * FROM view_aantal_reserveringen
De view wordt bewaard op de database en hoef je dus maar 1 keer aan te maken. Een voordeel van een view is dat je de onderliggende datastructuur kunt “verbergen”. Als je applicatie zijn data uit de views haalt maakt het in feite niet uit hoe je tabellen en kolommen heten, zolang de uitvoer van je view maar consistent is met je applicatie. Daarnaast kunnen rechten worden uitgedeeld op een view, zo zou je een gebruiker geen rechten hoeven te geven op al je tabellen maar alleen op de views, security dus!
Een view is read-only, je kunt er dus geen updates of inserts op uitvoeren, dit kan in sommige situaties echter wél door middel van rules, deze behandel ik niet aangezien ik persoonlijk het nut er niet helemaal van zie :)
Zie http://www.postgresql.org/docs/8.1/interactive/rules-views.html voor meer informatie hierover.
Pagina 6
PL/pgSQL functies en procedures
PostgreSQL is een erg uitgebreid systeem, om het nóg uitgebreider te maken heb je de mogelijkheid om je eigen functies te schrijven. Functies in een database zijn erg krachtig en vaak ook snel omdat het rechtstreeks op de server gebeurt. Functies / procedures kunnen worden geschreven in verschillende talen, het is zelfs mogelijk om PHP te gebruiken als taal!!! (zie http://www.commandprompt.com/community/plphp). De meest gebruikte is echter PL/pgSQL.
In een functie kun je gebruik maken van de standaard SQL-mogelijkheden, uitgebreid met foutafhandeling, loops, control-structures etc.
Simpel beginnen: Een sommetje. We maken een functie welke 2 getallen bij elkaar optelt en de uitkomst teruggeeft:
Hiermee wordt de functie “som” aangemaakt (of vervangen indien hij al bestaat). De functie heeft 2 argumenten nodig die beiden van het type INTEGER zijn, de returnwaarde van de functie is ook een INTEGER. Binnen de functie kun je de argumenten benaderen op nummer, welke beginnen bij 1.
De BEGIN en END geven het blok aan waarin bepaalde zaken plaatsvinden. Zo’n blok kan genest worden, variabelen welke je in een blok declareerd kun je in geneste blokken gebruiken maar niet in hoger gelegen blokken, de scope van een variabele beperkt zich dan dus tot het eigen blok en de blokken daarbinnen.
Je kunt deze functie op de volgende manier aanroepen:
Iets uitgebreider: Een wiskundige berekening; de faculteit van een getal berekenen. Bijvoorbeeld: De faculteit van 5 is 120: 5*4*3*2*1 = 120. Dit wordt ook wel geschreven als 5!
In dit voorbeeld komen de blokken en if-statements naar voren:
De aanroep van deze functie gebeurt op deze wijze:
In deze functie wordt een variabele gedeclareerd waarin we de meegegeven waarde opslaan, in een dieper blok genereren we een variabele “volgende” welke we als returnwaarde gebruiken. Je ziet dat dit een recursieve functie is, hij roept zichzelf aan totdat de eindwaarde is bereikt.
De mogelijkheden van functies en procedures in PL/pgSQL zijn echt oneindig, ik raad je aan om er over te lezen op http://www.postgresql.org/docs/8.1/static/plpgsql.html.
In een functie kun je gebruik maken van de standaard SQL-mogelijkheden, uitgebreid met foutafhandeling, loops, control-structures etc.
Simpel beginnen: Een sommetje. We maken een functie welke 2 getallen bij elkaar optelt en de uitkomst teruggeeft:
CREATE OR REPLACE FUNCTION som(INTEGER,INTEGER) RETURNS INTEGER AS'
BEGIN
RETURN $1+$2;
END;
' LANGUAGE 'plpgsql'
Hiermee wordt de functie “som” aangemaakt (of vervangen indien hij al bestaat). De functie heeft 2 argumenten nodig die beiden van het type INTEGER zijn, de returnwaarde van de functie is ook een INTEGER. Binnen de functie kun je de argumenten benaderen op nummer, welke beginnen bij 1.
De BEGIN en END geven het blok aan waarin bepaalde zaken plaatsvinden. Zo’n blok kan genest worden, variabelen welke je in een blok declareerd kun je in geneste blokken gebruiken maar niet in hoger gelegen blokken, de scope van een variabele beperkt zich dan dus tot het eigen blok en de blokken daarbinnen.
Je kunt deze functie op de volgende manier aanroepen:
SELECT som(2,3); // Geeft uitkomst 5
Iets uitgebreider: Een wiskundige berekening; de faculteit van een getal berekenen. Bijvoorbeeld: De faculteit van 5 is 120: 5*4*3*2*1 = 120. Dit wordt ook wel geschreven als 5!
In dit voorbeeld komen de blokken en if-statements naar voren:
CREATE FUNCTION faculteit(INTEGER) RETURNS INTEGER AS '
DECLARE
getal INTEGER;
BEGIN
getal := $1;
-- Controleer of we een geldig getal krijgen
IF getal IS NULL OR getal<0 THEN
RAISE NOTICE ''Geen geldig getal'';
ELSE
IF getal = 1 THEN
RETURN 1;
ELSE
DECLARE
volgende INTEGER;
BEGIN
volgende := faculteit( getal-1 )*getal;
RETURN volgende;
END;
END IF;
END IF;
END;
' LANGUAGE 'plpgsql';
De aanroep van deze functie gebeurt op deze wijze:
SELECT faculteit(5); // Uitkomst 120
In deze functie wordt een variabele gedeclareerd waarin we de meegegeven waarde opslaan, in een dieper blok genereren we een variabele “volgende” welke we als returnwaarde gebruiken. Je ziet dat dit een recursieve functie is, hij roept zichzelf aan totdat de eindwaarde is bereikt.
De mogelijkheden van functies en procedures in PL/pgSQL zijn echt oneindig, ik raad je aan om er over te lezen op http://www.postgresql.org/docs/8.1/static/plpgsql.html.
Pagina 7
Triggers
Het kan wenselijk zijn de database enkele acties uit te laten voeren op het moment dat er “iets” gebeurt met een tabel. Dat “iets” is bijvoorbeeld een INSERT, UPDATE of DELETE. In PostgreSQL kun je werken met triggers welke afgaan op een bepaalde gebeurtenis, ook wel event genoemd.
Stel dat we een reservering toevoegen, daarbij is het van groot belang dat de aankomstdatum vóór de vertrekdatum ligt (logisch toch). Je bouwt deze check natuurlijk in je applicatie, maar wat nu als je daar een fout maakt? Zou je het ook niet liever op je database vastleggen? Die is daar namelijk veel beter in en werkt ook nog als je aanpassingen maakt aan je applicatie of nog erger: als andere applicaties, waar je bijvoorbeeld geen invloed op hebt, gebruik maken van je database.
Een trigger roept altijd een functie aan, zoals reeds bekend schrijven we de functies in PL/pgSQL:
De functie is vrij eenvoudig van opzet, een IF-constructie controleert of de aankomstdatum groter is als de vertrekdatum, als dit het geval is wordt er een error gegenereerd, zo niet returned de functie netjes zijn trigger en wordt de wijziging / toevoeging aangebracht.
Om de triggerfunctie nu nog aan een tabel te koppelen dient de daadwerkelijke trigger nog aangemaakt te worden, dit kan met het volgende statement:
Je ziet hier dat ik de trigger afvuur vóór een INSERT of UPDATE, bij deze events mogen we in de aangeroepen trigger-functie gebruik maken van de variabele NEW. Dit is een zgn. ROWTYPE-variabele en bevat te velden van het nieuwe record welke je gaat invoeren of bijwerken.
Meer informatie over triggers vind je op http://www.postgresql.org/docs/8.1/static/plpgsql-trigger.html.
Stel dat we een reservering toevoegen, daarbij is het van groot belang dat de aankomstdatum vóór de vertrekdatum ligt (logisch toch). Je bouwt deze check natuurlijk in je applicatie, maar wat nu als je daar een fout maakt? Zou je het ook niet liever op je database vastleggen? Die is daar namelijk veel beter in en werkt ook nog als je aanpassingen maakt aan je applicatie of nog erger: als andere applicaties, waar je bijvoorbeeld geen invloed op hebt, gebruik maken van je database.
Een trigger roept altijd een functie aan, zoals reeds bekend schrijven we de functies in PL/pgSQL:
CREATE OR REPLACE FUNCTION check_reservering() RETURNS TRIGGER AS
'
BEGIN
IF( NEW.datum_aankomst > NEW.datum_vertrek ) THEN
RAISE EXCEPTION ''Aankomstdatum moet voor vertrekdatum liggen'';
END IF;
RETURN NEW;
END;
'
LANGUAGE 'plpgsql';
De functie is vrij eenvoudig van opzet, een IF-constructie controleert of de aankomstdatum groter is als de vertrekdatum, als dit het geval is wordt er een error gegenereerd, zo niet returned de functie netjes zijn trigger en wordt de wijziging / toevoeging aangebracht.
Om de triggerfunctie nu nog aan een tabel te koppelen dient de daadwerkelijke trigger nog aangemaakt te worden, dit kan met het volgende statement:
CREATE TRIGGER trigger_check_reservering
BEFORE INSERT OR UPDATE
ON reservering
FOR EACH ROW
EXECUTE PROCEDURE check_reservering();
Je ziet hier dat ik de trigger afvuur vóór een INSERT of UPDATE, bij deze events mogen we in de aangeroepen trigger-functie gebruik maken van de variabele NEW. Dit is een zgn. ROWTYPE-variabele en bevat te velden van het nieuwe record welke je gaat invoeren of bijwerken.
Meer informatie over triggers vind je op http://www.postgresql.org/docs/8.1/static/plpgsql-trigger.html.
Pagina 8
Check constraints en domains
Een vertaling van “constraint” is beperking, je kunt in PostgreSQL beperkingen leggen op bijvoorbeeld kolommen in je tabel. In zo’n check kun je vastleggen aan welk formaat dit gegeven moet voldoen.
Als voorbeeld: We hebben de kolom emailadres in de tabel klant, deze zou aan een bepaald formaat moeten voldoen:
De check op zich is een gewone reguliere expressie, want ja, ook die mag je gebruiken. De constraint wordt toegevoegd op de kolom “emailadres”. Data die nu in die kolom wordt gezet zal worden geweigerd als deze niet voldoet aan het formaat. Hiermee bewaak je dus consistentie, als er al foute data in je database staat zul je die eerst moeten oplossen, de constraint kan dan niet worden gemaakt.
Nog mooier: Domains
Zojuist heb je gezien hoe je eenvoudig een constraint kunt leggen op een bepaalde kolom. Het is echter mogelijk om je eigen datatypen aan te maken in PostgreSQL, één van die mogelijkheden kan met een “domain”.
Je hebt nu een domain-datatype aangemaakt, gefeliciteerd :)
Maar wat kan je hier nu mee? Je kunt dit datatype gaan gebruiken bij het aanmaken van kolommen aan tabellen:
Je hebt nu dus een kolom van het type “emailadres” welke automatisch wordt gechecked op het juiste formaat! Ook hier geldt dat een domein over de hele database kan worden gebruikt en slechts 1 keer hoeft worden aangemaakt.
Als voorbeeld: We hebben de kolom emailadres in de tabel klant, deze zou aan een bepaald formaat moeten voldoen:
ALTER TABLE klant ADD CONSTRAINT validmail CHECK
(
(emailadres)::text ~ '^[a-z0-9]+([_\\.-][a-z0-9]+)*@([a-z0-9]+([.-][a-z0-9]+)*)+\\.[a-z]{2,}$'::text
);
De check op zich is een gewone reguliere expressie, want ja, ook die mag je gebruiken. De constraint wordt toegevoegd op de kolom “emailadres”. Data die nu in die kolom wordt gezet zal worden geweigerd als deze niet voldoet aan het formaat. Hiermee bewaak je dus consistentie, als er al foute data in je database staat zul je die eerst moeten oplossen, de constraint kan dan niet worden gemaakt.
Nog mooier: Domains
Zojuist heb je gezien hoe je eenvoudig een constraint kunt leggen op een bepaalde kolom. Het is echter mogelijk om je eigen datatypen aan te maken in PostgreSQL, één van die mogelijkheden kan met een “domain”.
CREATE DOMAIN emailadres AS VARCHAR
CHECK(VALUE ~ '^[a-z0-9]+([_\\.-][a-z0-9]+)*@([a-z0-9]+([.-][a-z0-9]+)*)+\\.[a-z]{2,}$'::text);
Je hebt nu een domain-datatype aangemaakt, gefeliciteerd :)
Maar wat kan je hier nu mee? Je kunt dit datatype gaan gebruiken bij het aanmaken van kolommen aan tabellen:
ALTER TABLE klant ADD COLUMN nog_een_adres emailadres
Je hebt nu dus een kolom van het type “emailadres” welke automatisch wordt gechecked op het juiste formaat! Ook hier geldt dat een domein over de hele database kan worden gebruikt en slechts 1 keer hoeft worden aangemaakt.
Pagina 9
Conclusie
Je ziet dat er veel meer mogelijk is met databases dan alleen de normale inserts, updates, delete en select-statements. Veel applicatie-logica kan plaatsvinden op database-niveau, hier pleit ik ook voor. Een programmeur maakt fouten, je database doorgaans niet :)
Uiteraard kun je met een stel spannende procedures en triggers je database ook vergallen, daar moet je gewoon mee opletten. PostgreSQL is een mooi systeem dat gratis beschikbaar is, ook steeds meer hosters bieden het aan.
Veel succes, ik hoop dat je er iets aan hebt gehad en in de toekomst gebruik gaat maken van al die mogelijkheden.
Uiteraard kun je met een stel spannende procedures en triggers je database ook vergallen, daar moet je gewoon mee opletten. PostgreSQL is een mooi systeem dat gratis beschikbaar is, ook steeds meer hosters bieden het aan.
Veel succes, ik hoop dat je er iets aan hebt gehad en in de toekomst gebruik gaat maken van al die mogelijkheden.
Reacties
0